
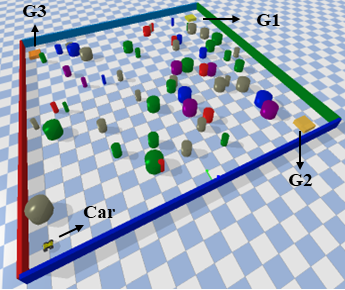
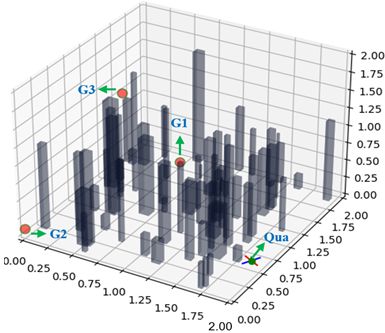
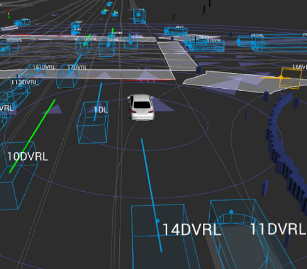
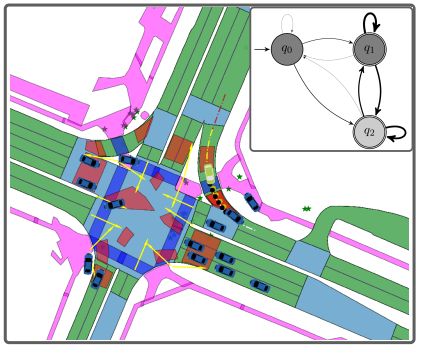
  | Mingyu Cai, Efan Aasi, Calin Belta, Cristian-Ioan Vasile Video / Paper Exploration is a fundamental challenge in Deep Reinforcement Learning (DRL) based model-free navigation control since typical exploration techniques for target-driven navigation tasks rely on noise or greedy policies, which are sensitive to the density of rewards. In practice, robots are always deployed in complex cluttered environments, containing dense obstacles and narrow passageways, raising natural spare rewards that are hard to be explored for training. Such a problem becomes even more serious when pre-defined tasks are complex and have rich expressivity. In this project, we focus on these two aspects and present a deep policy gradient algorithm for a task-guided robot with unknown dynamic systems deployed in a complex cluttered environment. Linear Temporal Logic (LTL) is applied to express a rich robotic specification. To overcome the environmental challenge of exploration during training, we propose a novel path planning-guided reward scheme that is dense over the state space, and crucially, robust to the infeasibility of computed geometric paths due to the black-box dynamics. To facilitate LTL satisfaction, our approach decomposes the LTL mission into sub-tasks that are solved using distributed DRL, where the sub-tasks can be trained in parallel, using Deep Policy Gradient algorithms. 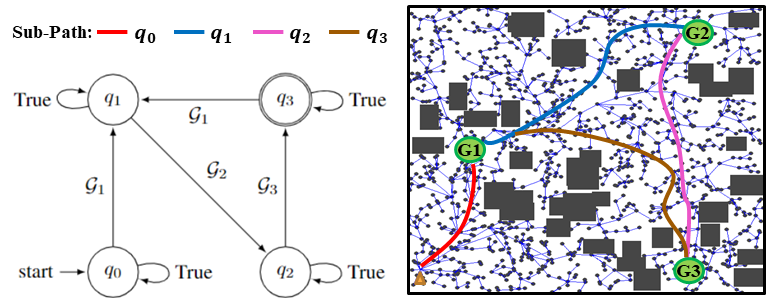 |
  | Danyang Li, Mingyu Cai, Efan Aasi, Calin Belta, Cristian-Ioan Vasile Paper1 / Paper2 / Related Literature Real-time and human-interpretable decision-making in cyber-physical systems is a significant but challenging task, which usually requires predictions of possible future events from limited data. Machine learning techniques using neural networks have achieved promising success for time-series data classification. However, the models that they produce are challenging to verify and interpret. In this project, we propose an explainable neural-symbolic framework for the classification of time-series behaviors. In particular, we use an expressive formal language, namely Signal Temporal Logic (STL), to constrain the search of the computation graph for a neural network. We design a novel time function and sparse softmax function to improve the soundness and precision of the neural-STL framework. As a result, we can efficiently learn a compact STL formula for the classification of time-series data through off-the-shelf gradient-based tools. We demonstrate the computational efficiency, compactness, and interpretability of the proposed method through urban-driving scenarios and naval surveillance case studies, compared with state-of-the-art baselines. 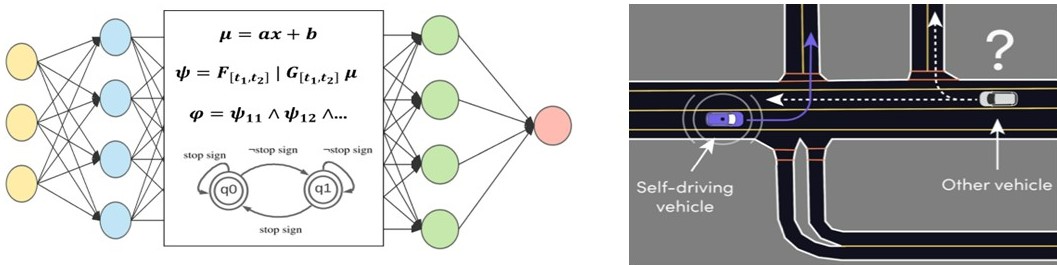 |
  | Mingyu Cai, Cristian-Ioan Vasile Video / Paper Reinforcement learning (RL) is a promising approach. However, success is limited towards real-world applications, because ensuring safe exploration and facilitating adequate exploitation is a challenge for controlling robotic systems with unknown models and measurement uncertainties. The learning problem becomes even more difficult for complex tasks over continuous state-space and action-space. In this project, we propose a learning-based control framework to satisfy high-level complex task while ensure safe during training. 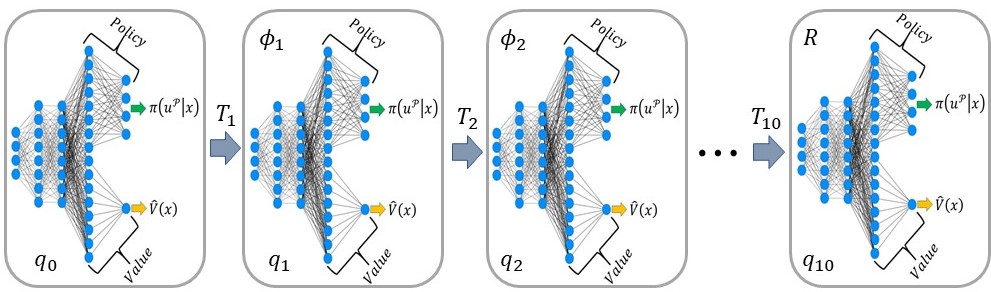 |
  | Zhangli Zhou, Shaochen Wang, Ziyang Chen, Mingyu Cai, Zhen Kan Video / Paper High-resolution representations are important for vision-based robotic grasping problems. Existing works generally encode the input images into low-resolution representations via sub-networks and then recover high-resolution representations. This will lose spatial information, and errors introduced by the decoder will be more serious when multiple types of objects are considered or objects are far away from the camera. To address these issues, we revisit the design paradigm of CNN for robotic perception tasks. We demonstrate that using parallel branches as opposed to serial stacked convolutional layers will be a more powerful design for robotic visual grasping tasks. In particular, guidelines of neural network design are provided for robotic perception tasks, e.g., high-resolution representation and lightweight design, which respond to the challenges in different manipulation scenarios. We then develop a novel grasping visual architecture referred to as HRG-Net, a parallel-branch structure that always maintains a high-resolution representation and repeatedly exchanges information across resolutions. Extensive experiments validate that these two designs can effectively enhance the accuracy of visual-based grasping and accelerate network training. 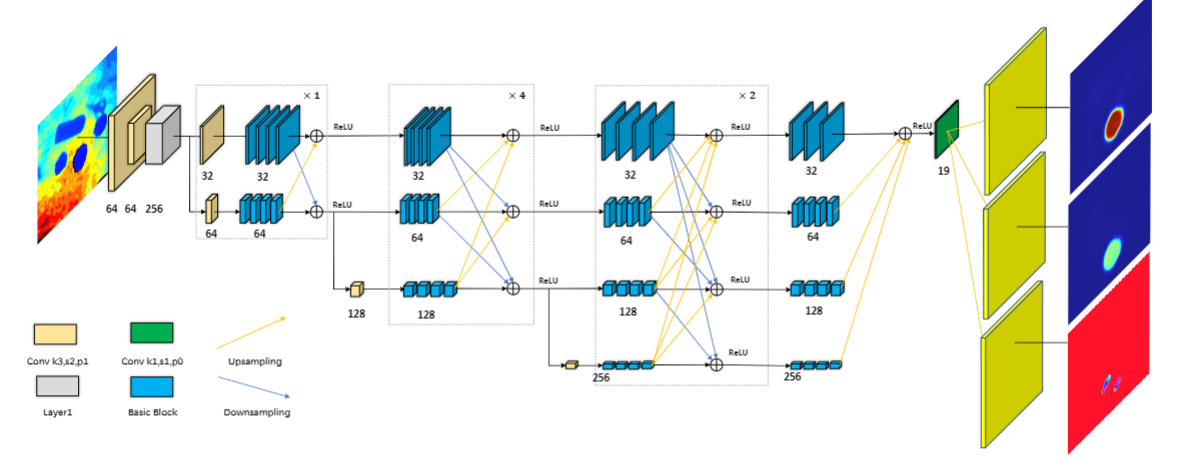 |
  | Mingyu Cai, Mohammadhosein Hasanbeig, Shaoping Xiao, Alessandro Abate, Zhen Kan Demo / Paper This project investigates the motion planning of autonomous dynamical systems modeled by Markov decision processes (MDP) with unknown transition probabilities over continuous state and action spaces. Linear temporal logic (LTL) is used to specify high-level tasks over infinite horizon such that the objective is to find controllers satisfying the complex tasks with probabilistic guarantees. A modular deep deterministic policy gradient (DDPG) is then developed to generate such policies over continuous state and action spaces. The performance of our framework is evaluated via an array of OpenAI gym environments. |
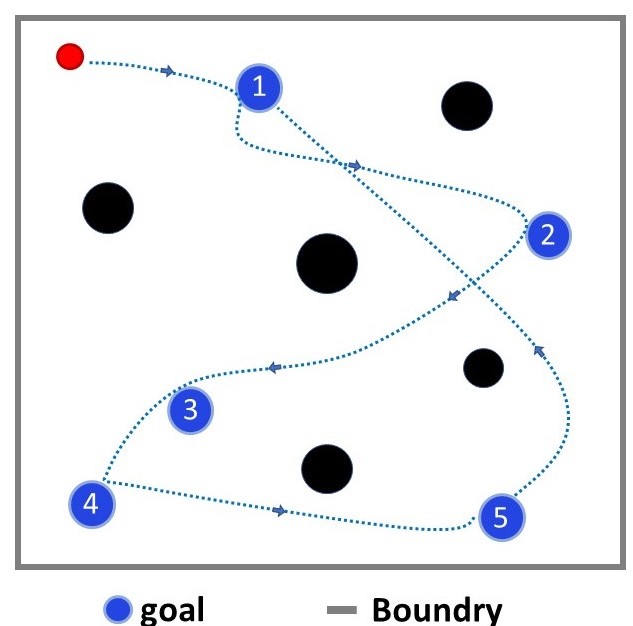
 | Mingyu Cai, Zhiliang Li, Hao Peng, Shaoping Xiao, Zhen Kan Video1 / Video2 / Video3 / Video4 / Paper1 / Paper2 This project considers online optimal motion planning of an autonomous agent subject to linear temporal logic (LTL) or Metric Inteval Temporal Logic (MITL) constraints. The environment is dynamic in the sense of containing mobile obstacles and time-varying areas of interest (i.e., time-varying reward and workspace properties) to be visited by the agent. Since user-specified tasks may not be fully realized (i.e., partially infeasible), this work considers hard and soft task-constraints, where hard constraints enforce safety requirement (e.g. avoid obstacles) while soft constraints represent tasks that can be relaxed to not strictly follow user specifications. The motion planning of the agent is to generate policies, in decreasing order of priority, to 1) formally guarantee the satisfaction of safety constraints; 2) mostly satisfy soft constraints (i.e., minimize the violation cost if desired tasks are partially infeasible); and 3) optimize the objective of rewards collection (i.e., visiting dynamic areas of more interests). |